Analyzing OPEC Member Crude Oil Production Quotas¶
Will Rodman | Data Science | Tulane University¶
Project Link: https://willcrodman.github.io¶
Introduction¶
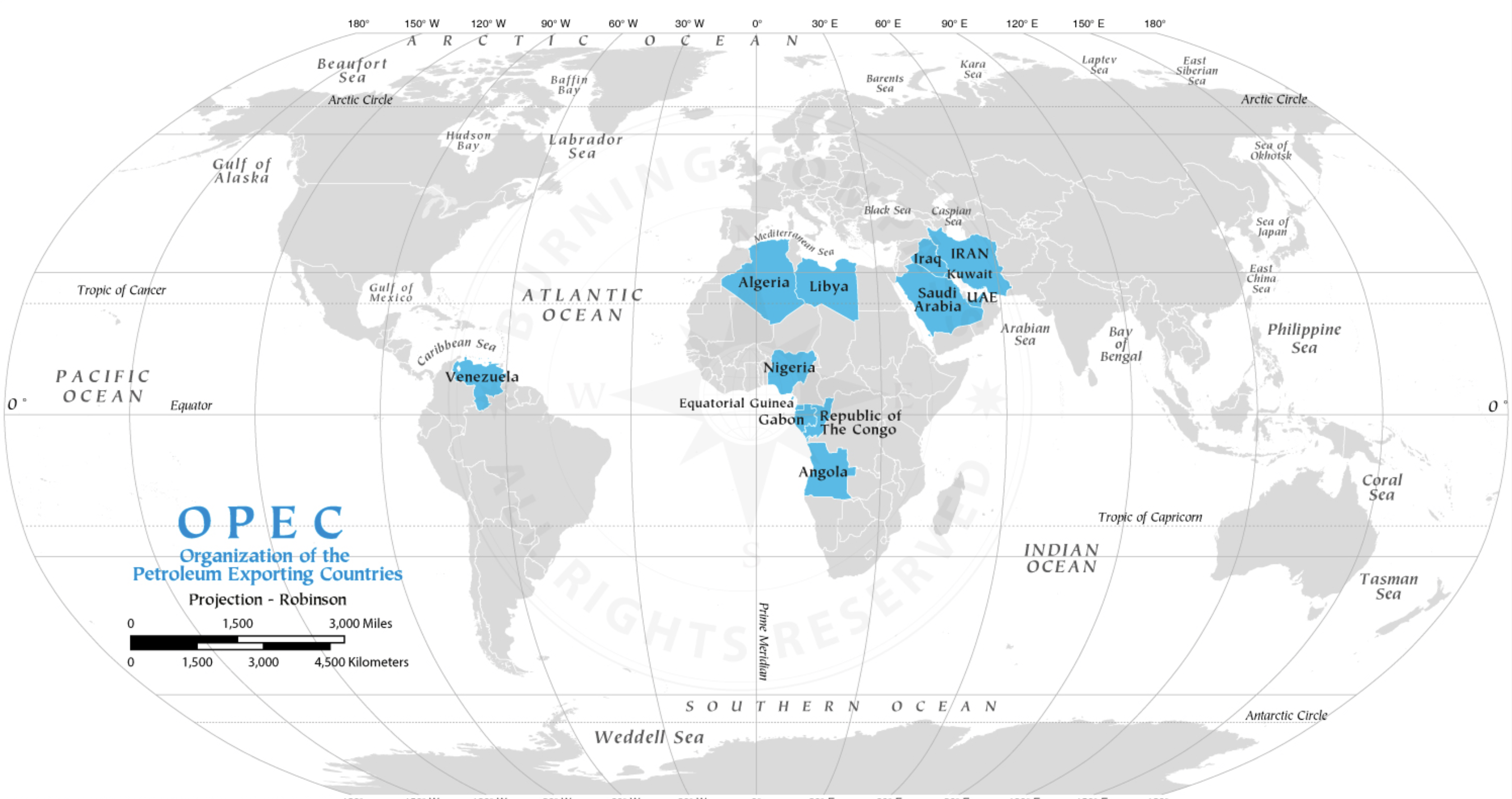
This project dives into data about OPEC (Organization of the Petroleum Exporting Countries) crude oil production and OECD (Organization for Economic Co-operation and Development) countries from 1960 to 2022. Including providing political context of OPEC and OECD, exploring their respective roles and significance in the global oil trade. The data source for this project is from the official OPEC website, which includes data such as crude oil production, demand, spot prices, refinery throughput, refinery capacity, and OPEC production quotas by country.
Founded in 1960, OPEC comprises a group of petroleum-exporting nations. OPEC was created with the primary aim of asserting collective control over their oil resources and global oil trade. OPEC's founding members included Iran, Iraq, Kuwait, Saudi Arabia, and Venezuela. Over the years, the organization has expanded to include several other member nations, totaling 13.
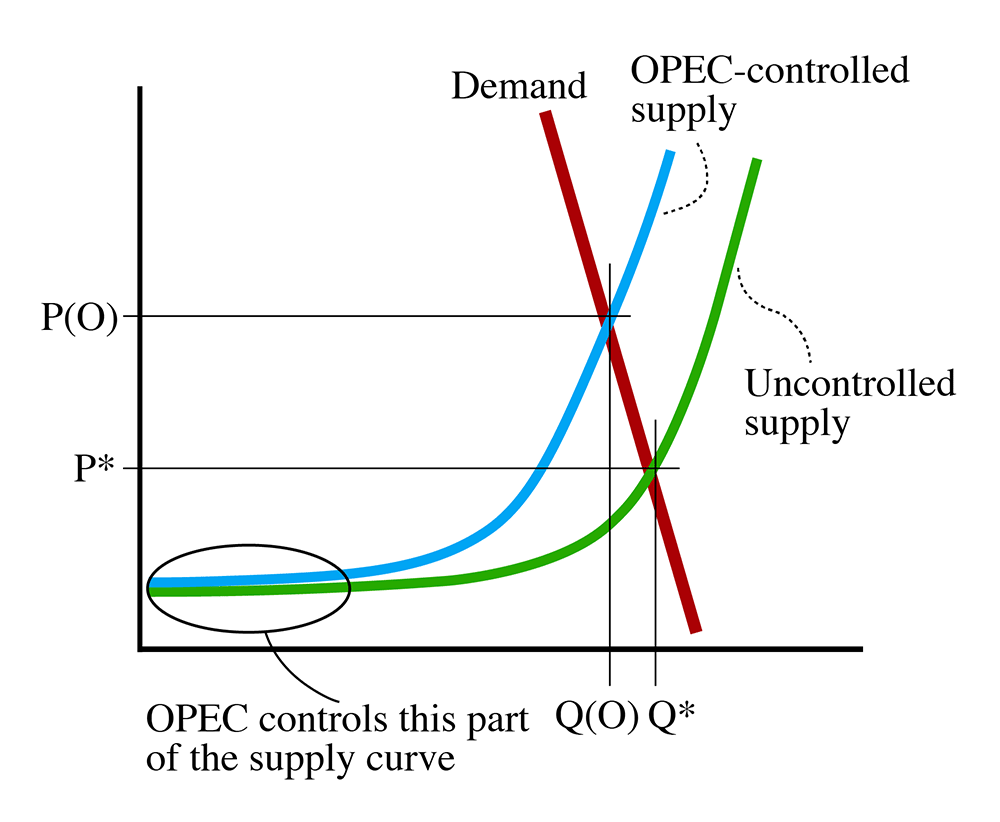
It is important to focus on OPEC member nations due to their global importance as petroleum exporters. Alongside OECD countries, who are reliant on oil imports to meet their energy needs, and have historically been affected by changes in OPEC production quotas and embargoes. This by fixing production and suppliers, OPECs behaves like as cartel-style supplier.